MTG - Music Technology Group
Publication of "OMAR-RQ: Self-Supervised Audio Encoders for Music Understanding"
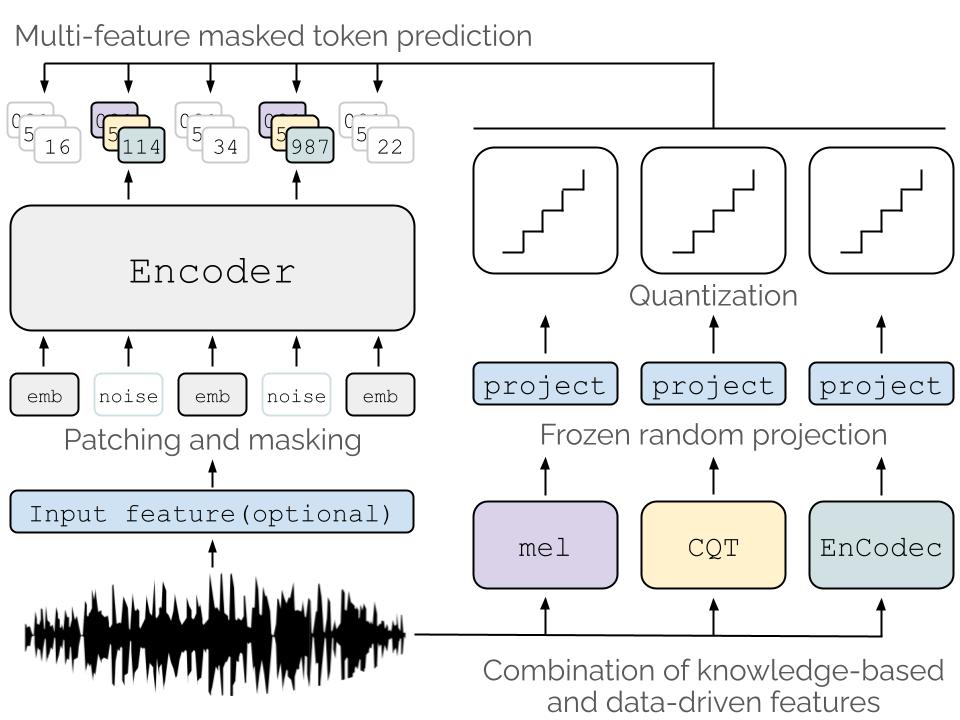
The article “OMAR-RQ: Self-Supervised Audio Encoders for Music Understanding” is a result of our previous project (July–November 2024) at the Barcelona Supercomputing Center, which was recently recognized as a Highlighted Activity by the Spanish Supercomputing Network. The research was developed by MTG members Pablo Alonso, Pedro Ramoneda, Recep Oğuz Araz, Andrea Poltronieri, and Dmitry Bogdanov, and will be presented at the ACM Multimedia 2025 conference in Dublin, Ireland.
OMAR-RQ is a family of large-scale self-supervised audio encoders based on masked token prediction and trained on more than 330,000 hours of music audio. With 580 million parameters, the models achieve state-of-the-art performance on multiple music understanding tasks, including tagging, pitch and chord recognition, structure segmentation, and piano difficulty estimation. The key strengths of OMAR-RQ are its scale (roughly double the dataset size and parameter count of previous comparable models) and its use of multi-feature learning objectives, which make it a robust foundation for fine-tuning in multimodal applications and audio LLMs.
This research direction has already been extended through two follow-up projects: “Language and Audio Representation Models for Sound and Music Understanding” at the Barcelona Supercomputing Center, and “Text and Audio Representation Models for Music Understanding” supported by the NVIDIA Academic Grant Program.
This project was developed within the framework of La Cátedra UPF-BMAT en Inteligencia Artificial y Música (TSI-100929-2023-1), one of whose objectives is the promotion and development of open-source models such as the OMAR-RQ family. All training and evaluation pipelines, along with the pretrained model weights, are openly available in the project repository.
Read the full preprint: OMAR-RQ: Open Music Audio Representation Model Trained with Multi-Feature Masked Token Prediction
Activity in the frame of:
Cátedra UPF-BMAT en Inteligencia Articial y Música (TSI-100929-2023-1). Project funded by Secretaría de Estado de Digitalización e Inteligencia Artificial, the European Union-Next Generation EU, and by BMAT Music Innovators, the Music Operating System
