Minz Won wins the WWW 2018 Challenge: Learning to Recognize Musical Genre
(Text by Minz Won, taken from his blog in Github, the original entry here). See also the UPF news (Spanish / Catalan)
I won the “WWW 2018 Challenge: Learning to Recognize Musical Genre” with Jay Kim. This post describes our approach for the challenge. Full paper is available here.
Intro
About challenge
This year, the Web conference, also known as WWW, newly organized a challenge track. Learning to Recognize Musical Genre was one of four programs in the challenge track. A goal of our challenge was to recognize the musical genre of a piece of music of which only a recording is available. The data was a subset of FMA dataset.
Evaluation
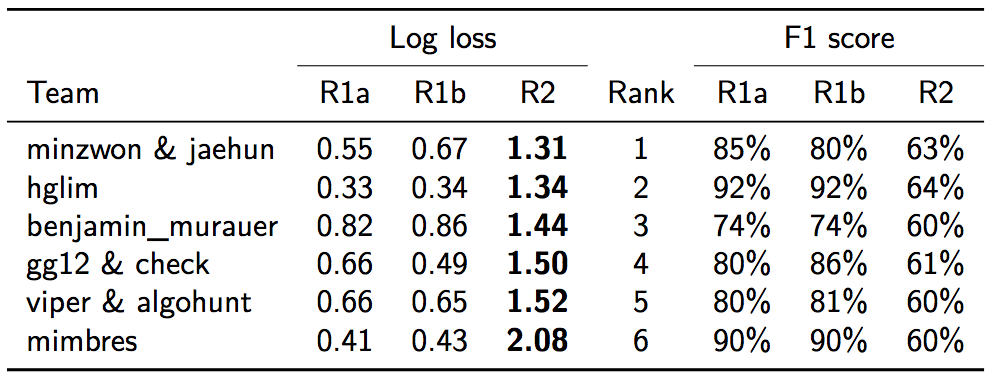
The challenge consists of two rounds. In the first round, participants are provided a test set of 35,000 clips of 30 seconds each, and they have to submit their predictions for all the 35,000 clips. The primary metric for evaluation was the Mean Log Loss. In the second round, which is the final round, participants have to wrap their models in a Docker container. Organizers evaluate those against a new unseen test set.
Team
I teamed up with Jay Kim, who is my previous colleague at MARG and currently a PhD student at TU Delft.
Our approach
Motivation
In the beginning of the challenge, each of us had own idea for the model design. So, we decided to work separately and ensemble the learned features from each model. However, during the experiment, we figured out some critical factors that can affect the final result.
- Since the FMA genre annotations have been done by uploaders, they are noisy and not reliable. (I think someone has to report errors and refine the dataset.)
- Most of genre annotations (5028 out of 5152 albums) have been done in album level even if they have multiple genres in a single album.
- There are a lot of duplicated artists in a train set. (25000 tracks of train set were from 5152 unique albums.)
- For round 1, test accuracy does not follow the validation accuracy.
Participants could check their results on the leader board interactively for the round 1. We got the best result when we overfit our model to the train set and stop the iteration at a certain heuristic point. One of our speculation for this phenomenon was that the test set of round 1 has shared artists with the train set.
Since we didn’t know the artist distribution of the round 2 and we wanted our model to learn more generalized representations, we needed more reliable targets to learn such representations. To this end, Jay proposed to use clusters as targets of our models instead of noisy genre annotations.
Proposed method
Artist Group Factors (AGFs)
Due to the reasons that I mentioned above, targetting artist label might be beneficial for this challenge. There was also a previous research that utilized artist labels for the representation learning. However, due to data sparsity, only a few tracks are assigned per artist. It can be beneficial to group artist labels into clusters of similar artists, avoiding learning bottlenecks caused by large numbers of classes. To this end, we proposed Artist Group Factors (AGFs).

The main idea of extracting AGFs is to cluster artists based on meaningful feature sets that allow for aggregation at (and beyond) the artist level. Let’s take a look at the pipeline step-by-step.
- From the music data, extract features or tags. i.e. Essentia features, Mel-Frequency Cepstral Coefficients (MFCC), dMFCC, or subgenre tags.
- Learn feature dictionaries with obtained features using K-Means clustering. If you use tags, no need for this step.
- Each artist can be represented using a Bag-of-Word (BoW) feature vector. For example, let’s assume that we have 5 clusters from previous step, and there is an artist called Barbara. If three songs of Barbara belong to cluster #1 and four songs belong to cluster #3, her feature vector might be [3, 0, 4, 0, 0]. We can also do the same with tags.
- Apply Latent Dirichlet Allocation (LDA) to transform artist-level BoW vectors into AGF representations.
We generated four different AGFs using Essentia features, MFCC, dMFCC, and subgenre tags.
Model design
We trained five networks targetting genre tags and each of four AGFs. Same Convolutional Neural Network (CNN) structures have been used. You can check detailed structure from the paper.
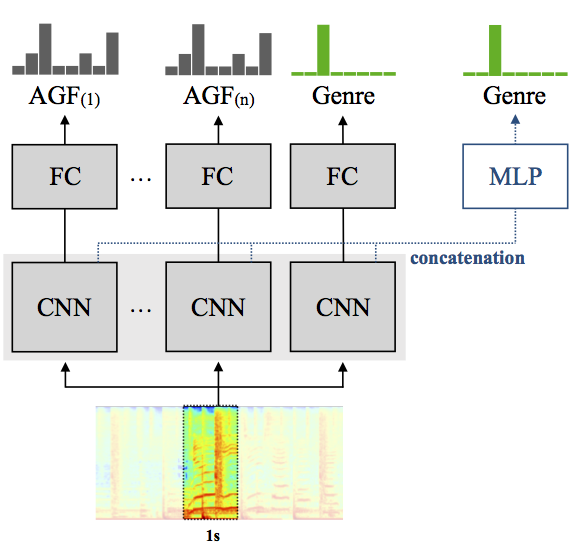
Finally, we transferred all of learned representations to predict genre tags which was the goal of this challenge. A simple Multi Layer Perceptron (MLP) has been used for this step.
Discussion
- FMA dataset has to be refined.
- Log-loss of the round 2 was higher than our expectation even though we used AGFs. But we don’t know the distribution of round 2 test set.
- To determine the effectiveness of AGFs, they have to be testified on other dataset with more elaborate split methods.
- Evaluation metrics such as LogLoss, F1 are imperfect. Higher score in these metrics do not always mean the better model.
Next destination… Spotify-RecSys Challenge