Premiat un treball sobre mètodes d’alineació de lletra i àudio en veu cantada de l’òpera de Beijing
Fet per membres del Grup de Recerca en Tecnologia Musical i considerat el millor article a la 6a. edició de l’International Workshop Folk Music Analysis (FMA) celebrat del 15 al 17 de juny a Dublín (Irlanda).
En un treball inscrit en el context de l’òpera de Beijing, des del 2010 Patrimoni Cultural Inmaterial de l’Humanitat, els investigadors Georgi Dzhambazov, Yile Yang , Rafael Caro Repetto i Xavier Serra, membres del Grup de Recerca en Tecnologia Musical (MTG) del Departament de Tecnologies de la Informació i les Comunicacions (DTIC) de la UPF, han proposat un nou mètode per a l’estudi de l’alineació de la lletra amb l’àudio en la interpretació a cappella, un estil de música vocal o cant sense acompanyament instrumental que, per les seves característiques, permet estudiar millor la fonètica en la veu cantada. L’objectiu de la recerca va ser dissenyar un algorisme capaç d’obtenir millors resultats que els existents, i va guanyar el premi al millor article en la 6a. edició del International Workshop Folk Music Analysis (FMA 2016) celebrat del 15 al 17 de juny a Dublín (Irlanda).
 [CC BY 2.0 (http://creativecommons.org/licenses/by/2.0)], via Wikimedia Commons) https://commons.wikimedia.org/wiki/File%3ABeijing-Opera2.jpg") Algunes característiques de l’òpera de Beijing
Algunes característiques de l’òpera de Beijing
El jingjù 京剧 o també conegut com a òpera de Beijing, és interpretada en mandarí estàndard amb alguna aportació dialectal, i les seves lletres es basen en principis poètics. S’estructura en rodolins de dos versos i cadascun d’ells es divideix en tres dous que alhora es componen de dos a quatre caràcters escrits. En general, una ària comença amb un part més lenta que es va accelerant gradualment per expressar estats d’ànims més intensos. Així doncs, per emfatitzar la semàntica d’una frase o d’acord amb la trama, l’actor té l’opció de sostenir la vocal de la síl·laba final del dou.
Com explica Georgi Dzhambazov, primer autor del treball, “normalment, les tècniques per alinear lletra i àudio en veu cantada es basen en les tècniques desenvolupades per veu parlada. Però hi ha un parell de problemes: la pronunciació de la veu cantada no es ben bé la de la veu parlada, i la durada de las vocals, més llargues en la veu cantada, afecten a aquestes tècniques”.
El que s’ha fet en aquest treball per assolir l’objectiu de l’estudi, dissenyar un algorisme capaç d’obtenir millors resultats, ha estat fer servir un model estadístic que tingui en compte els canvis de duració de la parla, concretament l’anomenat: “model ocult de Markov amb duració explícita” (Duration-explicit Hidden Markov Model, DHMM).
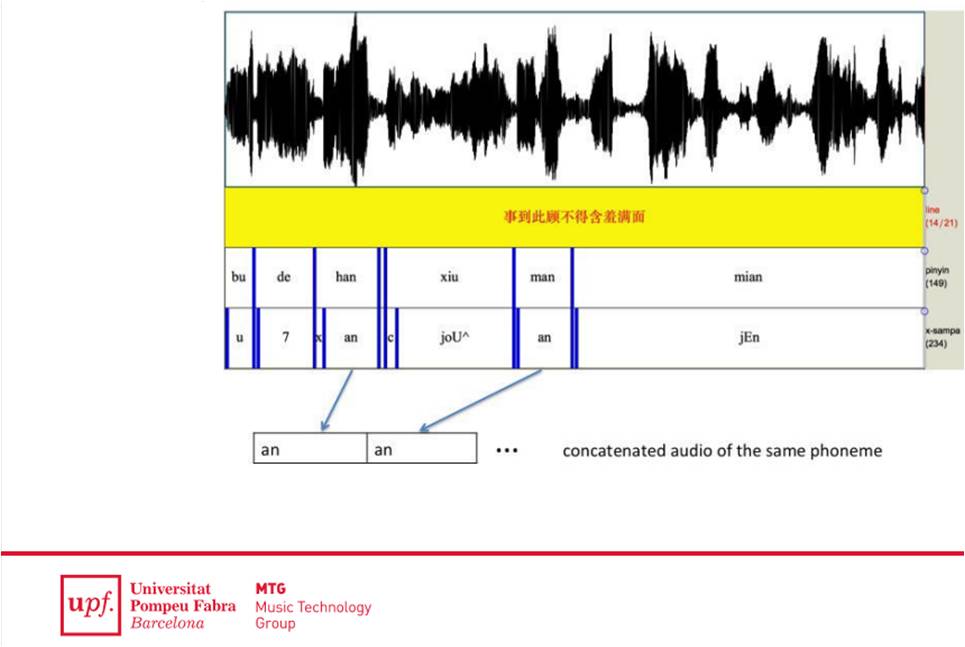 Aleshores, aquest model s’ha emprat en representacions fonètiques extretes directament de mostres de veu cantada, enlloc de fer-lo servir en mostres de veu parlada, com és habitual. És a dir, el DHMM s’ha aplicat a gravacions a cappella del jingjù que, per la seva idiosincràsia, no presenta acompanyament instrumental que pugui afectar l’anàlisi fonètic.
Aleshores, aquest model s’ha emprat en representacions fonètiques extretes directament de mostres de veu cantada, enlloc de fer-lo servir en mostres de veu parlada, com és habitual. És a dir, el DHMM s’ha aplicat a gravacions a cappella del jingjù que, per la seva idiosincràsia, no presenta acompanyament instrumental que pugui afectar l’anàlisi fonètic.
A més, per predir la duració de les síl·labes s’ha afegit al model una sèrie de normes que s’han obtingut del coneixement teòric del jingjù, és a dir, el fet que l’última síl·laba d’un dou normalment és més llarga, i encara més si és la síl·laba final d’un banshi , “els patrons rítmics en què s’estructuren les àries i que normalment van de més lents a més ràpids”, explica Rafael Caro Repetto, coautor del treball i expert en aquest gènere musical xinès. I com també ha destacat , “precisament, aquest darrer aspecte és un dels principis fonamentals del projecte CompMusic: incloure informació cultural específica del gènere de música objecte d’estudi en el desenvolupament de les eines computacionals”.
CompMusic és un projecte europeu que té com a objectiu principal desenvolupar sistemes d’anàlisi automàtic de tradicions musicals diferents de les occidentals, conforme a les respectives especificitats culturals. La música tradicional xinesa és una de les tradicions musicals que estudia el MTG que lidera Xavier Serra, amb el suport de l’European Research Council i que està continuant gràcies a l’ajut Proof of Concept aconseguit el 2015 amb l’objectiu de comercialitzar algunes de les tecnologies desenvolupares en el marc del projecte CompMusic.
Treball de referència:
Georgi Dzhambazov, Yile Yang , Rafael Caro Repetto, Xavier Serra (2016), “Automatic Alignment of Long Syllables in a Cappella Beijing Opera”, Folk Music Analysis: FMA 16: 6th. International Workshop, 15-17 Juny, 2016.
Example of lyrics-to-audio alignment of a cappella Beijing opera from Georgi Dzhambazov on Vimeo.