Teaching machines how to listen to the environment
Teaching machines how to listen to the environment
by Eduardo Fonseca
We are constantly hearing sounds, and we are pretty good at recognizing them and knowing what they mean. Wouldn’t it be great if machines could do the same? If they could track what is going on in the environment, or summarize for us what is happening in an audio recording. Wouldn’t it be great if machines could help people with hearing problems to perceive sounds? If they could tell when the microwave is ready or when someone just knocked at the door?
Recognizing all kinds of everyday sounds like environmental, urban or domestic sounds, is an emerging research field with many interesting applications. But to teach machines how to recognize sounds, large amounts of reliably labeled audio data are essential for training them, and currently there is a lack of open audio data for this type of research. To address this issue, we started to develop a framework to support the creation of datasets for research in sound recognition.
In this blog post, we explain the Freesound Annotator, our proposed framework for creating audio datasets, we describe the Freesound Dataset (FSD), the main dataset we are building, and the applications that this dataset will be useful for.
What is Freesound Annotator?
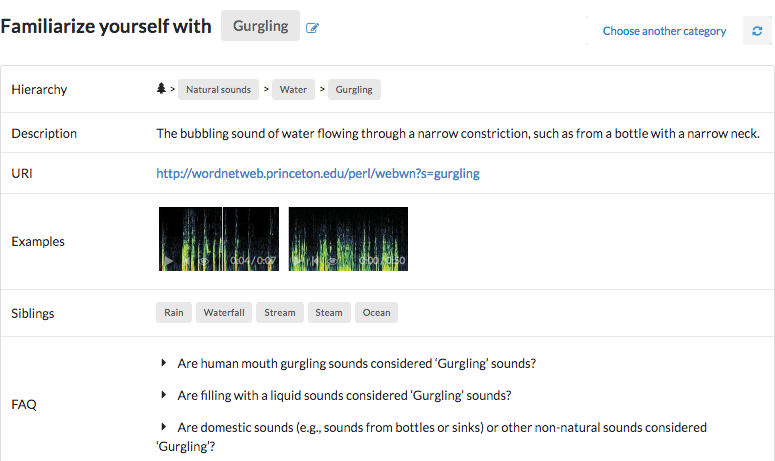
Freesound Annotator is a platform for the creation of open audio datasets. That is, collections of annotated audio recordings that can be freely used by researchers to work on audio analysis and recognition problems. Freesound Annotator supports the creation and exploration of open audio collections with a few particularities: the creation is done collaboratively by crowdsourcing annotations, and the audio content comes from Freesound - the sound sharing site created and maintained by the MTG, with over 400,000 sounds.

In the Freesound Annotator you can contribute to the creation of audio datasets by providing annotations and you can explore categories of audio clips. Soon you will be able to download timestamped releases of the datasets (meaning they can be expanded over time) and flag mislabeled or faulty audio clips. All datasets will be openly available under Creative Commons licenses.
Why did we decide to do this?
The main reason is to foster research in automatic sound recognition, a field of study that aims to develop algorithms for the automatic identification of sounds by machines, which in turn will allow us to develop technologies to improve and exploit Freesound. In other research fields, like computer vision, several large-scale open datasets are available, and we’ve witnessed how these datasets have triggered important advances. But in the sound recognition field, this has not happened yet. In this field, researchers used to be limited to few domain-specific and not-so-large datasets (although the connotation of size changes rapidly over time). Whether it is about domestic sounds, urban sounds, or other domain, each of those datasets encompass just a small bit of the variety of sounds in our everyday environment. Plus, some of the existing datasets have fallen short for current machine learning needs, like the data hungry deep learning approaches. While the value of current datasets is unquestionable, we believe there is a need for more diverse and comprehensive ones.
And then arrived Google’s AudioSet: the largest dataset of sound events, consisting of over 5000h of audio, labeled with over 500 event categories. This has partially solved the two mentioned problems by providing plenty of audio data and a set of sound categories covering a wide range of everyday sounds, structured as an ontology. Nevertheless, there is a major shortcoming in AudioSet: the audio clips are taken from YouTube videos that have usage restrictions, which make the audio tracks not freely-distributable. This is why AudioSet is composed of audio features instead of the actual audio signals, which limits researchers in their experimentations. To address all these issues, we decided to develop the Freesound Annotator, with the objective of creating large-scale and openly-available audio datasets that can support research in sound event recognition, thus without the limits of the existing datasets.
Our main dataset: The Freesound Dataset (FSD)
The first dataset that we began to create with Freesound Annotator is the Freesound Dataset (FSD): a large-scale, general-purpose dataset composed of Freesound content annotated with labels from Google’s AudioSet Ontology. One of the characteristics of Freesound is the diversity of its sounds (ranging from human and animal sounds to music and sounds made by things), uploaded by thousands of users across the globe. We wanted our first dataset to reflect this, and for this reason we used the AudioSet Ontology to annotate the clips in FSD.
FSD started with the automatic assignment of thousands of Freesound clips to the categories in the AudioSet Ontology, and from that these assignments have been validated manually to check whether the initial assignments were correct. To this end, we developed a validation tool in Freesound Annotator, with many features to facilitate the manual validation and to make it reliable and efficient.
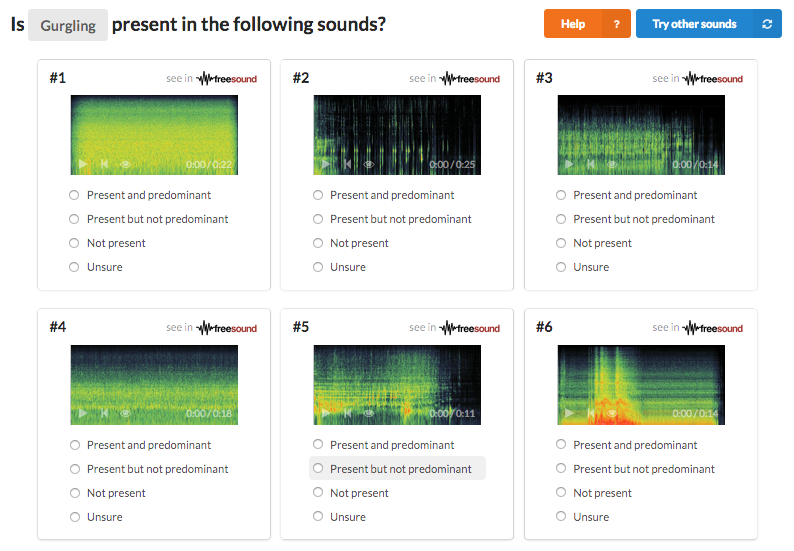
The validation has been done by crowdsourcing the task; 432 awesome volunteers have helped in the cause!! But we also were awarded a Google Faculty Research Award 2017 to support the creation of FSD, which allowed us to hire a team of research assistants to complement the crowdsourcing. After an intense work by many people, the first release of FSD will be available in mid 2019, and will feature tens of thousands of audio clips across around 200 sound categories, which will make it the largest freely-distributable dataset of real-world sound events. FSD will include audio waveforms, ground truth annotations, and metadata plus acoustic features.
But how is this useful?
The technology that can be developed with these datasets, and FSD in particular, enables many interesting applications. For example, it allows the automatic description of multimedia content, which can be used for automatic audio subtitling or captioning. Also, in the context of multimedia hosting sites, it can power tools to enhance the exploration and retrieval of the content, for example in Freesound, to quickly help users find what they are looking for.
Sound event recognition has a direct impact on healthcare through context-aware applications that could change the lives of thousands. For instance, it can be used to improve the life quality of the hearing impaired, either through mobile apps or with enhanced hearing aids. It can also be used to develop intelligent domestic assistants that react to events occurring at home, as well as to identify urban noise sources as an aid to urban planning against noise pollution. It also opens the door to automatic acoustic monitoring applications like wildlife monitoring and many other applications yet to be explored. One of the things that we find more exciting is that all these applications have a clear impact on human welfare, thus with a great potential of positive social impact in multiple areas.

Achievements so far, and what’s next!
Even though FSD has not yet been released, we’ve already reached a few milestones. We have released two smaller datasets. The first one is called FSDKaggle2018, which was used for a machine learning competition on the Kaggle platform called the Freesound General-Purpose Audio Tagging Challenge, in collaboration with Google’s Sound Understanding Team. The second dataset we released is called FSDnoisy18k, which aims to foster the investigation of label noise in sound event classification. The work developed so far has led to the publication of four research papers in major conferences and workshops like ISMIR, DCASE, FRUCT and ICASSP. Part of this work has been possible thanks to several awards to support the project, including a Google Faculty Research Award 2017 and an AI grant 2017.
We expect to make the first release of FSD soon and this is just the beginning. For example, we plan to release deep learning models pre-trained with FSD that can be easily used for the recognition of sounds. We hope these resources will be useful not only for the research community and the society at large, but also for the industry.
This should never end since we aim to keep expanding and improving FSD with additional data continuously. In the process we will be adding new features to Freesound, making it even more valuable than what it already is.
The members of the team that are making all this possible are Xavier Favory, Eduardo Fonseca, Frederic Font, and Jordi Pons, with contributions from Andres Ferraro and Alastair Porter and the supervision of Prof. Xavier Serra. We will keep working to develop datasets and technology that will allow machines to hear and interpret sounds like people do :)